Kafka internals (and GDPR-compliance)
The other day at work, I was tasked with checking whether our Kafka setup is GDPR-compliant or not. It turned out, that our setup is not compliant. Luckily, the service was not yet live, and the Kafka topics didn’t contain any PII.
I learned a lot about Kafka internals and what you have to do, to be GDPR-compliant. Hopefully, you can take something from this post too.
Basics
Topics 📢
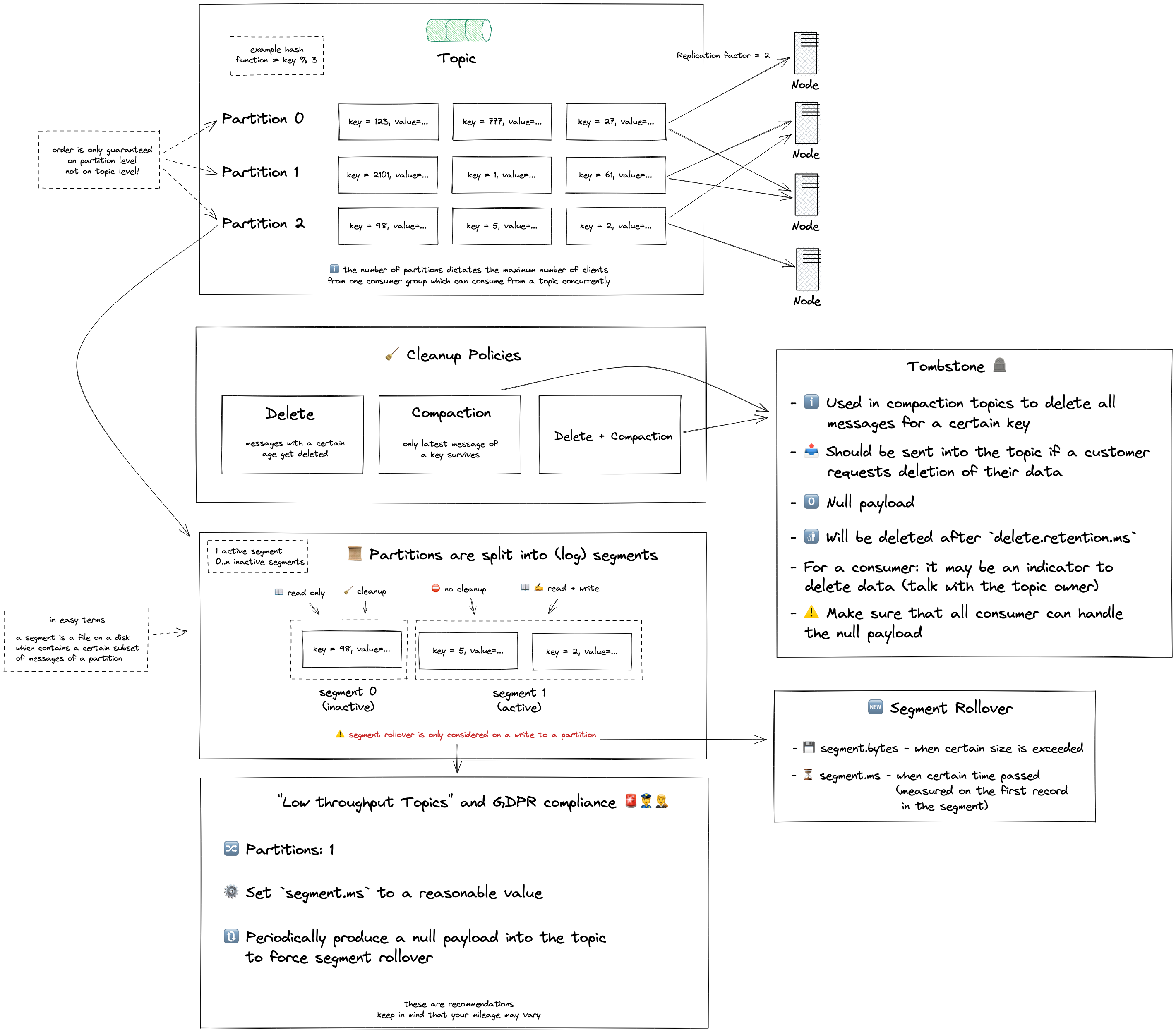
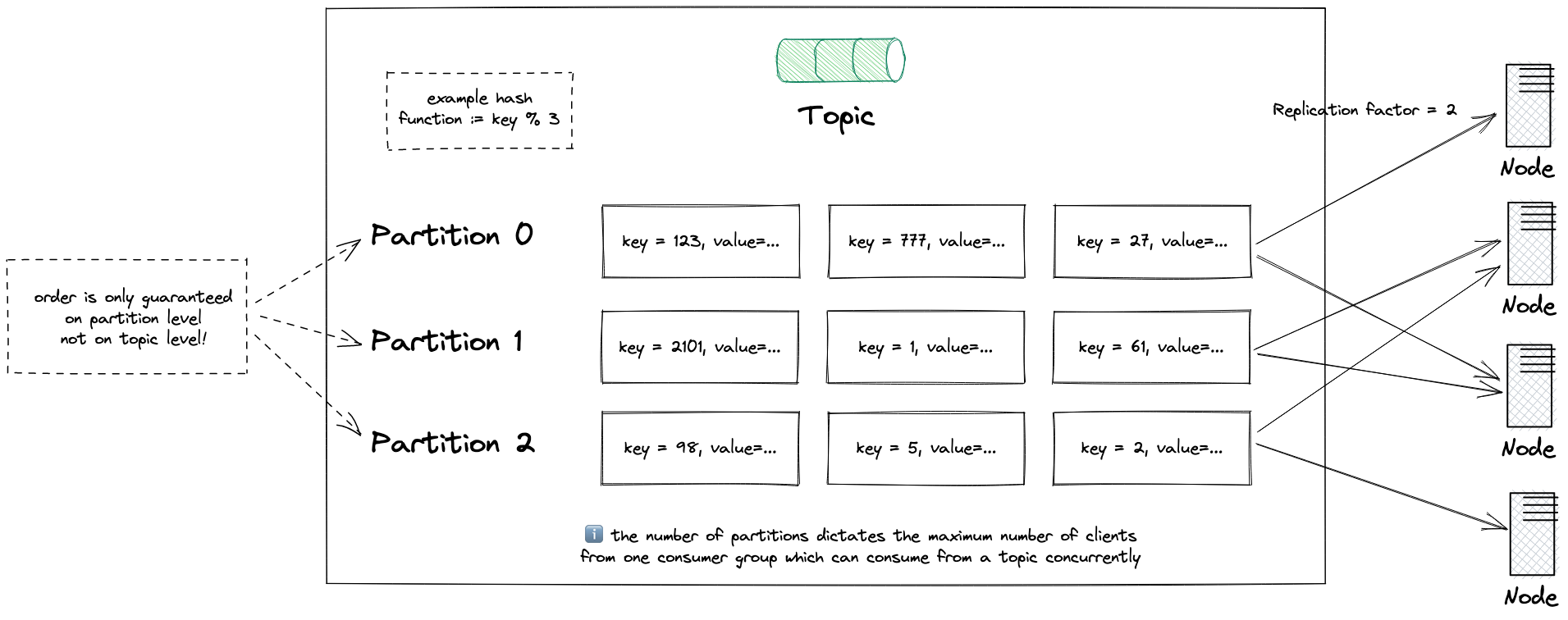
As you probably know, a topic is split up into multiple partitions.
Could be 1 or n partitions.
To put it simply: partitions are the way that Kafka provides scalability.
When you produce a message to a certain topic, a hash of the key will be calculated and used to assign your message to a certain partition (see the Java code).
Since the used hashing algorithm is deterministic, messages with the same key will be sent to the same partition.
Consumer group
Multiple consumer groups can read from a topic parallel. Every consumer group has their own offset (basically the position for the last read message for every partition) and are therefore independent of each other. A consumer group can consist of multiple clients.
For example: if you have a service which reads from a topic, and you scale horizontally, make sure all the instances belong to the same consumer group. Otherwise, your service will read the messages multiple times.
ℹ️ The number of clients in a consumer group for a certain topic is limited by the number of partitions. Kafka distributes the available partitions to every client from a consumer group.
⚠️ It is – more or less – easy possible to increase the number of partitions for a topic, but not to decrease them. Keep that in mind when you initially configure your topic.
Message order
Kafka guarantees message ordering, messages that were sent in a specific order, will be written by the broker in the same order and all consumer will read them in the same order.
⚠️ But keep in mind, that this guarantee is only given on partition level not on topic level.
Cleanup policies 🧹
Kafka knows three cleanup policies:
delete– deletes old segments (what the hell is a segment? later more) when the retention time or size limit is reachedcompact– retains only the latest message for each key (essentially deletes older messages with the same key)delete,compact– a combination of the above
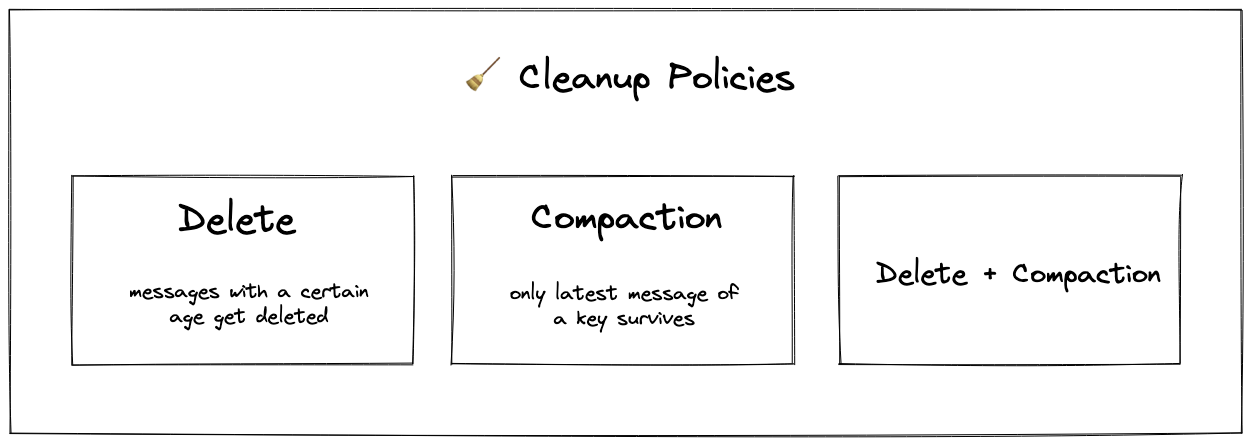
Compaction is usually used if the latest message renders every previous message useless.
Imagine the value of the message is the current email of a customer: {"email":"foo@bar.com"}.
Would you need every other message of the customer, or just the latest?
If the latter is the case, you can use compaction.
Tombstone 🪦
Tombstone (markers) are simply a message with a null payload.
⚠️ Don’t mix up null with "null" (String) as payload.
The latter won’t be recognized as a Tombstone marker from Kafka.
Tombstones are mostly used in compaction topics to delete messages with a certain key.
They will be deleted after a certain time too (config: delete.retention.ms).
The tombstone could also seen as an indicator, that every consumer of this topic should take a certain action. For instance, delete data which belongs to the entity represented by the message key.
⚠️ On implementation of your consumer class, you should make sure that your code can handle null-payloads.

Segments
Every partition is split into multiple segments.
There is at least 1 active segment and there can be 0..n inactive segments.
New messages are written into the active segment.
Inactive segments are never modified and only read from.
What is a segment exactly? Basically, a file on the disk which contains a subset of messages for a certain partition. Segments follow the same concept as log files, which get “rotated”. That means new logs (think: messages) get written into the active file. If the file reaches a certain age or size, it eventually gets rotated and becomes inactive. A new segment is opened which is the new active one.
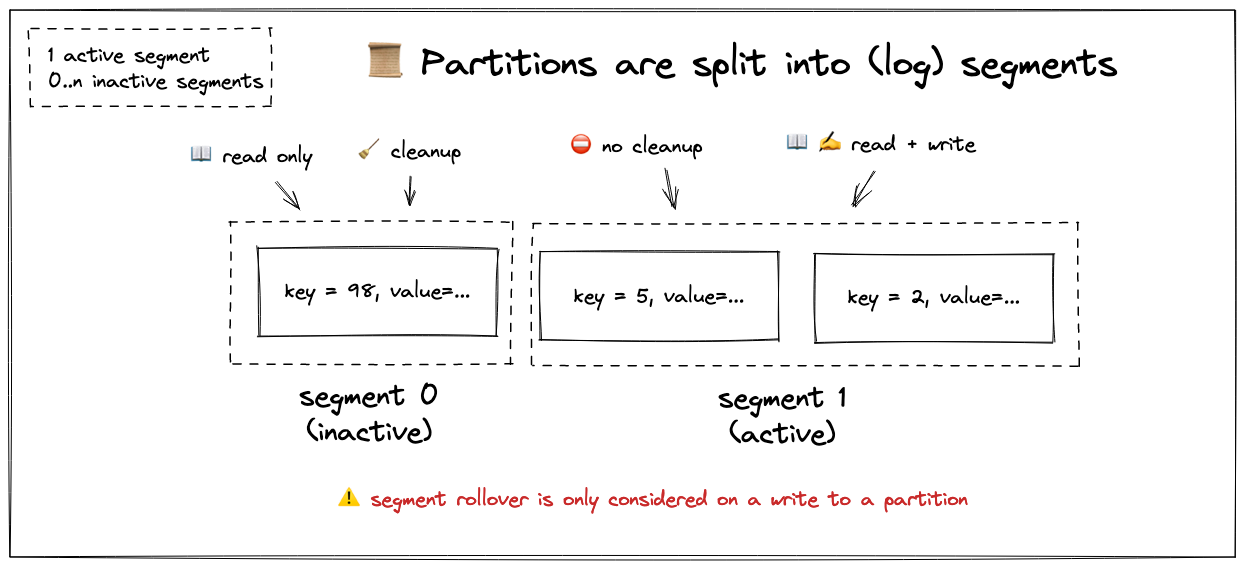
The active segment is never target of cleanups (delete and compact, see above).
Only inactive segments are cleaned.
Segment rollover happens only when a message is produced into a partition.
The configuration properties segment.bytes and segment.ms are the threshold for size and age of a segment.

⚠️ If you have numerous partitions on a low throughput topic, there might be some partitions which don’t get new messages for a long(er) period. This means the rollover on the active segment is never considered, and therefore the messages are not subject to cleaning. Depending on the topic configuration, this can lead to saving PII longer as legally allowed.
GDPR-compliance on low throughput topics 🧑⚖️
To avoid the outlined problem, we configured our low throughput topic with only 1 partition.
Set the segment.ms to a reasonable value and set up a job which produces a message into the topic periodically.
This way we force the segment rollover independent of if a ‘real’ produces sends messages or not.

Summary
- A topic is split into partitions
- A partition is split into segments
- The number of partitions is the upper bound for the number of clients in a consumer group
- The active segment is not cleaned
- Carefully adjust low throughput topics to be GDPR-compliant